GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models

PubDate: June, 2020
Teams: Google Research
Writers: Hongyi Xu, Eduard Gabriel Bazavan, Andrei Zanfir, William Freeman, Rahul Sukthankar, Cristian Sminchisescu
PDF: GHUM & GHUML: Generative 3D Human Shape and Articulated Pose Models
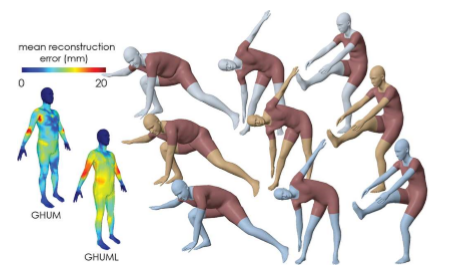
Abstract
We present a statistical, articulated 3D human shape modeling pipeline, within a fully trainable, modular, deep learning framework. Given high-resolution complete 3D body scans of humans, captured in various poses, together with additional closeups of their head and facial expressions, as well as hand articulation, and given initial, artist designed, gender neutral rigged quad-meshes, we train all model parameters including non-linear shape spaces based on variational auto-encoders, pose-space deformation correctives, skeleton joint center predictors, and blend skinning functions, in a single consistent learning loop. The models are simultaneously trained with all the 3d dynamic scan data (over 60,000 diverse human configurations in our new dataset) in order to capture correlations and ensure consistency of various components. Models support facial expression analysis, as well as body (with detailed hand) shape and pose estimation. We provide fully train-able generic human models of different resolutions- the moderate-resolution GHUM consisting of 10,168 vertices and the low-resolution GHUML(ite) of 3,194 vertices-, run comparisons between them, analyze the impact of different components and illustrate their reconstruction from image data. The models will be available for research.